Summary
We are going to implement a distributed, concurrent, in-memory hash-table. We will be testing the code on Intel Xeon Phi coprocessors (Latedays cluster).
Background
The applications of in-memory hashtable in real world applications are countless. In-memory hashtables allow constant time lookups. Cuckoo hashing is a efficient scheme for resolving hash collisions of values of hash functions in a table, with worst-case constant lookup time.
Having entire hashtable in one node is infeasible in many large-scale scenarios. Single node might not have enough memory required to store entire hashmap. Also, accessing hashmap stored on a single node can become a bottleneck from the performance perspective. Hence, arises the need to have a distributed in-memory hashmap, without compromising on the performance.
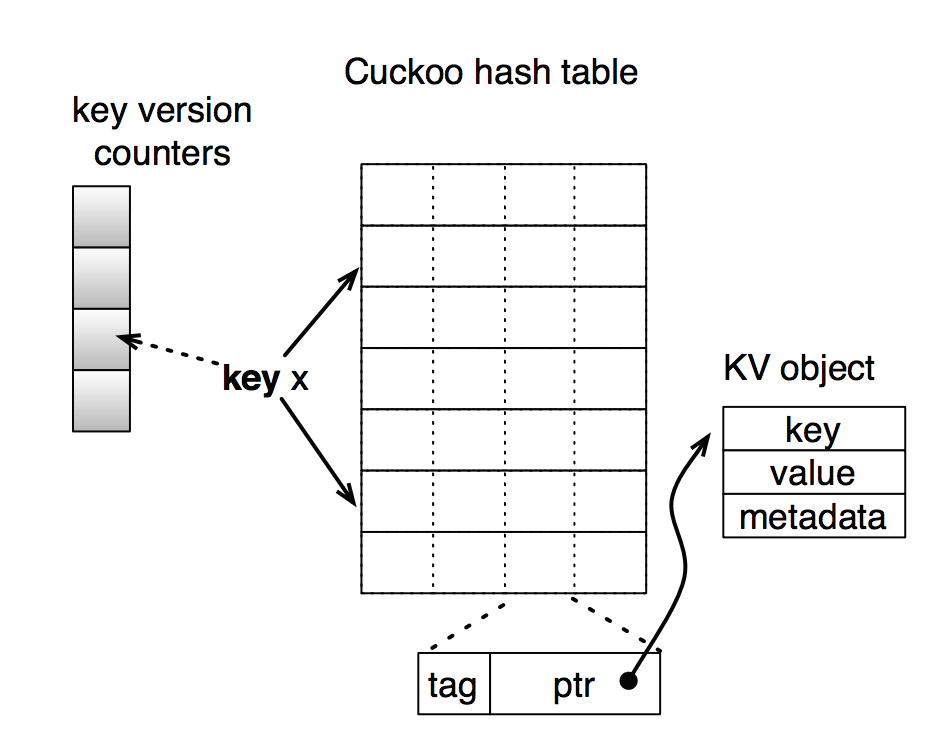
Challenges
The primary challenge of this project is gaining a sufficient understanding of the Cuckoo hashing and possibilities of parallelising it. Also, scaling the hashtable to multiple nodes should a difficult task.
Resources
We will be running and testing our code on Latedays cluster machine. We will start our codebase from the scratch and will be using some of the optimizations trick discussed in MemC3[1] for a single node case.
Goals and Deliverables
- Plan to achieve
- Sequential implementation of the Hashmap on a single node.
- Parallel implementation of in-memory hashmap using cuckoo hashing for a single node.
- Scaling this hashtable to multiple nodes in distributed setting.
- Hope to achieve
- Dynamic Load Balancing: Dynamically remapping keys and generating in-memory hashtable to prevent a single node becoming a hotspot. Later, even this load balancer can be replicated to avoid becoming a hotspot itself.
- Confirgurability to run in single node mode: In ceratin situation it’s benifical to run hashtable on a single node to avoid overhead associated setting. For that mode, we will try implement in-memory hashtable with disk IO support.
Platform Choice
We will implement our project in C++ and will be using latedays for testing and development. However, the solution will be generic enough so that it can run on any x86 platform.
Schedule
- 4/10 - 4/16: Do literature survey and implement sequential hashtable on a single node.
- 4/17 - 4/24: Implement basic version of in-memory hashmap using cuckoo hashing for a single node.
- 4/25 - 5/1: Complete and optimise in-memory hashmap using cuckoo hashing for a single node.
- 5/2 - 5/8: Scale this hashtable in distributed environment.
- 5/9 - 5/11: Final optimisation and report preparation
References
[1] https://www.cs.cmu.edu/~dga/papers/memc3-nsdi2013.pdf